Caddy 默认的 HTTPS 支持与 Cloudflare CDN 配合使用时无法正常下发证书,这里介绍通过一定的配置让它们正常配合工作。
Home Assistant 安装后的一些初始设置
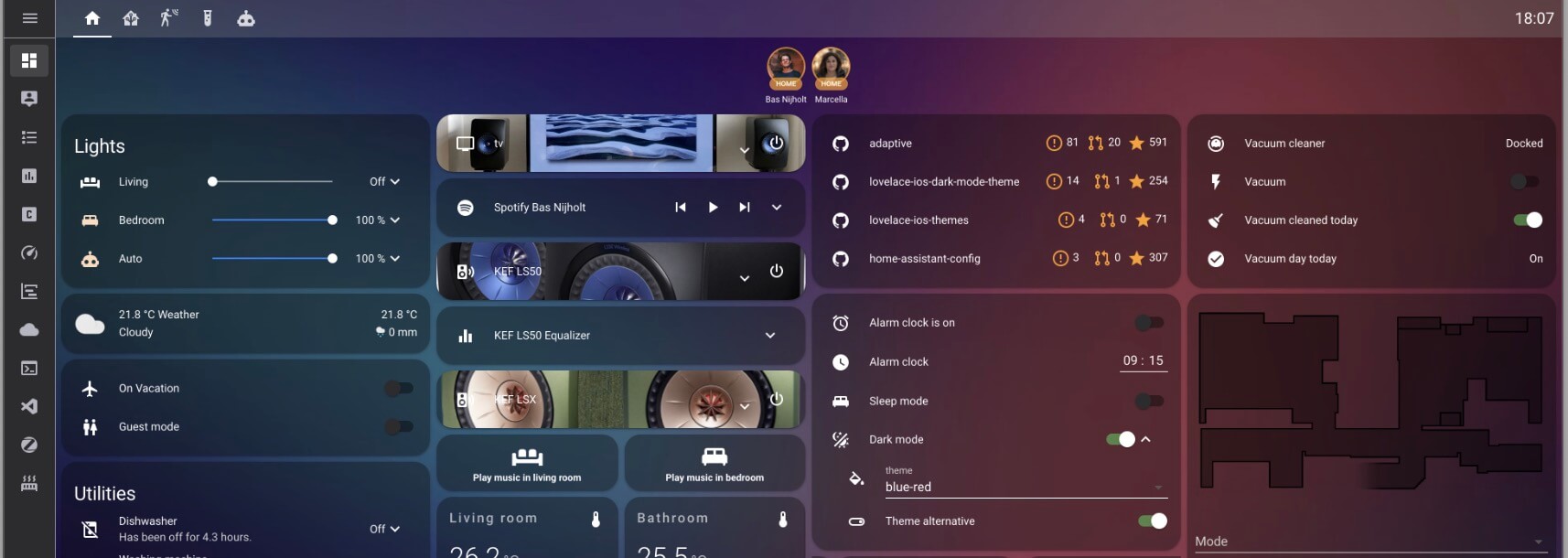
PVE 虚拟机快速安装 HomeAssistant OS 教程
一加 ColorOS 手动安装 Magisk 获取 root
简要记录 ColorOS 13 获取 root 的过程。需要手机已解锁 Bootloader,电脑已安装 adb 和 fastboot,准备手机固件的全量包。
安卓7以上版本安装 Charles 证书进行 HTTPS 抓包的方法
有几年没做移动端开发了,发现 Android 7 以上版本即使安装了 Charles 导出的证书也无法解析 HTTPS 请求,最终 root 手机后找到了解决方法。主要是如何安装证书到系统证书目录。
学习 Emby Server 解锁及优化
支持 VLESS 的 subconverter
原版的 subconverter 不支持 VLESS 协议,根据相关 issue找到了支持 VLESS 协议的方法。
使用 Flex 和 Grid 实现自动填充剩余宽度或高度
通过 CSS Flex 和 Grid 布局实现父容器宽度/高度不定,子元素自动填充剩余宽度/高度。并且在子元素内容过大时,保证内容不要超出父容器。
使用 Gitbook Cli (honkit) 生成 PDF,Markdown 转 PDF
我们希望有一种在线文档可以方便地导出 PDF 文档,并且导出的 PDF 排版最好与在线文档一致。最终我们选择了已经多年未更新的 Gitbook Cli (的替代品: honkit)。
Linux 和 macOS 平台配置 mosdns 为系统服务
mosdns 是一个支持分流等功能的 DNS 转发器。在 mosdns wiki 文档中对系统服务安装方式说明不太详尽,主要是解决如何注册服务并设置为开机自动运行。